Below is a thingum I made that roughly maps out (and even animates!) our itinerary. Though illustrative, it may not be completely accurate, so don't rely upon it for good information.
Saturday, December 28, 2013
Going to New Zealand! Today!
These next several posts will chart our impending journey to New Zealand, which begins on a CapMetro bus this morning at 9:30am and ends with our arrival to Auckland Int. Airport at 12:50pm on 12/31 (for us, there is no December 30th...) Along the way, we have two excellent layovers (Los Angeles & Nadi, Fiji) so expect to hear more about these places as well.
Below is a thingum I made that roughly maps out (and even animates!) our itinerary. Though illustrative, it may not be completely accurate, so don't rely upon it for good information.
Below is a thingum I made that roughly maps out (and even animates!) our itinerary. Though illustrative, it may not be completely accurate, so don't rely upon it for good information.
Monday, December 16, 2013
Ode to an Autobus
As a student at the University of Texas, I am entitled to ride all Capital Metro public transportation completely gratis, and I wanted to take a moment to express my gratitude. I would've been paying $2/day almost every day this semester (about 72 days, according to this source), so I've saved $144 dollars so far.
I enjoy riding buses and trains; I like their consistency - the same times, the same drivers - but I also like their novelty - the strange new people you are exposed to from the safety of your seat. I like riding my bike, too, but only sometimes, and not too far. There again, the bus provides: a pull-down bike-rack hangs off of the front of each one and there is usually a vacant slot.
The car-as-status-symbol is lower-middle class at best; the upper classes have developed more effective ways of signifying their social clout. Now, cars a just a hassle, and it makes good sense to have something else ferry you around. Instead of waiting for an insufferably cold car to heat up, I get on a preheated bus. Instead of sitting in infuriating traffic, or wasting my time in tedious driving, I sit quietly in perfect leisure - usually reading, sometimes writing - on a bus. Instead of the many indignities of parking, including the small fortune you pay for your trouble, I am deposited conveniently near my location, free of charge.
Enrique Penalosa, the former Mayor of Bogota, Colombia, gave a TED talk a few years ago, and he began by saying "an advanced city is not one where even the poor use cars, but rather one where even the rich use public transport." He also pointed out that in Amsterdam, over 30% of the population commutes by bicycle (and the Netherlands has higher income per capita than the US). 100 years ago there were few cars and even fewer roads; now there are traffic jams that last hours, even days. Just think: because of the development of now-developing countries, in the next 50 years, it is estimated that more than half of the cities that will exist in the year 2060 will be built. Cars cannot, and will not, continue to be the standard, self-driving or otherwise.
I enjoy riding buses and trains; I like their consistency - the same times, the same drivers - but I also like their novelty - the strange new people you are exposed to from the safety of your seat. I like riding my bike, too, but only sometimes, and not too far. There again, the bus provides: a pull-down bike-rack hangs off of the front of each one and there is usually a vacant slot.
The car-as-status-symbol is lower-middle class at best; the upper classes have developed more effective ways of signifying their social clout. Now, cars a just a hassle, and it makes good sense to have something else ferry you around. Instead of waiting for an insufferably cold car to heat up, I get on a preheated bus. Instead of sitting in infuriating traffic, or wasting my time in tedious driving, I sit quietly in perfect leisure - usually reading, sometimes writing - on a bus. Instead of the many indignities of parking, including the small fortune you pay for your trouble, I am deposited conveniently near my location, free of charge.
Enrique Penalosa, the former Mayor of Bogota, Colombia, gave a TED talk a few years ago, and he began by saying "an advanced city is not one where even the poor use cars, but rather one where even the rich use public transport." He also pointed out that in Amsterdam, over 30% of the population commutes by bicycle (and the Netherlands has higher income per capita than the US). 100 years ago there were few cars and even fewer roads; now there are traffic jams that last hours, even days. Just think: because of the development of now-developing countries, in the next 50 years, it is estimated that more than half of the cities that will exist in the year 2060 will be built. Cars cannot, and will not, continue to be the standard, self-driving or otherwise.
Tuesday, December 10, 2013
Typing Speed and the Woes of 1-β
My six-year-old macbook (a black one, before the pro) is still operational, but it has burned through (literally) several batteries, and, unless I pay apple the $129.00 they want for a new one, it is going to remain about as portable as your average desktop PC. That's fine for around-the-house applications, but when your academic adviser (who is retiring this year) asks, "Where's your computer!" every time you have a meeting with her, you know it's about time to get a new, backpack-friendly means of computing.
So I did! Sometime in late October I became the proud owner of a Lenovo ThinkPad T-430s (Intel i7 (3rd Gen, 2.9 GHz) processor, 16 GB of RAM and a 128 GB SSD, with an expansion bay for which I have a 500 GB HDD, an additional battery, and a DVD Multi drive) This was another high-dollar craigslist transaction (iPod, TI-89, electric guitar...) that went off without a hitch.
Anyway, it's supposed to have this improved ThinkPad keyboard, and reviews I had read online while I was shopping around suggested that it might help to increase one's typing speed. Around the same time, someone on Facebook posted something about play.typeracer.com, which assigns random text for you to type, calculates your WPM, and keeps a log of all the data from your past "races". It's great fun!
I created two accounts--one for the laptop, one for desktop (control)--and alternated playing "races" on each. I did about five on each keyboard in a sitting, over six sittings, giving me 30 games completed on each.
Subjectively, I couldn't tell much. I seemed to be getting similar speeds regardless of which keyboard I was using.
With this data, I generated some graphs and ran two t-tests. Though "single-subject" designs are not common, I figured that it would be statistically similar to a "within-subjects" anova or a repeated-measures t-test. Given this, I figured that a sample size of ~30 per group would be sufficient.

R input:

R input:
But to really know for sure, I wanted an estimate of the power of this test. Power, for those unfamiliar, is the probability of detecting differences between the groups given that there are actually differences. It is defined as one minus the probability of a type II error (failing to reject the the null hypothesis given that it is false), and can be calculated using estimates of the effect size and the sample size. A standard measure of effect size is Cohen's d which can be calculated by the following:
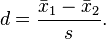 where s is equal to
where s is equal to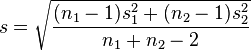 (from wikipedia)
(from wikipedia)
It's essentially a measure of the the difference between group means in terms of a pooled standard deviation. You can define function in R that will calculate this for you:
That's a vanishingly small effect size! Power is going to be abysmal! You can calculate the power using the pwr package.
n = 820!!! I would need 820 trials per keyboard for the test to be powerful enough to detect differences of that effect size. Well, I suppose I won't be continuing this project any time soon. I'm satisfied to know that my average WPM is 84.78 with a standard deviation of 7.77.
So I did! Sometime in late October I became the proud owner of a Lenovo ThinkPad T-430s (Intel i7 (3rd Gen, 2.9 GHz) processor, 16 GB of RAM and a 128 GB SSD, with an expansion bay for which I have a 500 GB HDD, an additional battery, and a DVD Multi drive) This was another high-dollar craigslist transaction (iPod, TI-89, electric guitar...) that went off without a hitch.
Anyway, it's supposed to have this improved ThinkPad keyboard, and reviews I had read online while I was shopping around suggested that it might help to increase one's typing speed. Around the same time, someone on Facebook posted something about play.typeracer.com, which assigns random text for you to type, calculates your WPM, and keeps a log of all the data from your past "races". It's great fun!
I created two accounts--one for the laptop, one for desktop (control)--and alternated playing "races" on each. I did about five on each keyboard in a sitting, over six sittings, giving me 30 games completed on each.
Subjectively, I couldn't tell much. I seemed to be getting similar speeds regardless of which keyboard I was using.
With this data, I generated some graphs and ran two t-tests. Though "single-subject" designs are not common, I figured that it would be statistically similar to a "within-subjects" anova or a repeated-measures t-test. Given this, I figured that a sample size of ~30 per group would be sufficient.
R input:
> boxplot(desktop, laptop, data=data, main="Typing Speed Data", xlab="Desktop (left) vs. Laptop (right)", ylab="Words per Minute (GPM)", col="lightblue")Above are boxplots for the data. Notice the means appear to be roughly equal (laptop mean 84.4, desktop mean 85.2), but that there's a lot more variation on the desktop keyboard. Below shows the scores on the desktop keyboard (blue) vs. the laptop keyboard (red) over time (should be 30 games, I typoed).
R input:
g_range<- range(70, desktop, laptop)The t-test results showed no difference between the means. First I ran a normal t-test (t.test(laptop, desktop)), treating desktop scores and laptop scores as two independent group (t = -0.3792, df = 55.536, p-value = 0.7059). I then tried a repeated measures t-test (t.test(laptop, desktop, paired=T)) and got (t = -0.3929, df = 29, p-value = 0.6973)
plot(desktop, type="o", col="blue", ylim=g_range, axes=FALSE, ann=FALSE)
axis(1, at=1:29)
axis(2, at=65:110)
box()
lines(laptop, type="o", pch=22, lty=2, col="red")
title(main="GWM over time for different keyboards")
title(xlab="Typing games played (1-29)")
title(ylab="Words per minute (WPM)")
legend(1, g_range[2], c("desktop","laptop"),cex=0.8,col=c("blue","red"),pch=21:22, lty=1:2);
But to really know for sure, I wanted an estimate of the power of this test. Power, for those unfamiliar, is the probability of detecting differences between the groups given that there are actually differences. It is defined as one minus the probability of a type II error (failing to reject the the null hypothesis given that it is false), and can be calculated using estimates of the effect size and the sample size. A standard measure of effect size is Cohen's d which can be calculated by the following:
where s is equal to(from wikipedia)It's essentially a measure of the the difference between group means in terms of a pooled standard deviation. You can define function in R that will calculate this for you:
> cohens_d <- function(x, y) {+ lx <- length(x)- 1+ ly <- length(y)- 1+ md <- abs(mean(x) - mean(y)) ## mean difference (numerator)+ csd <- lx * var(x) + ly * var(y)+ csd <- csd/(lx + ly)+ csd <- sqrt(csd) ## common sd computation+ cd <- md/csd ## cohen's d+ }> res<-cohens_d(desktop, laptop)> res[1] 0.09792157
That's a vanishingly small effect size! Power is going to be abysmal! You can calculate the power using the pwr package.
> pwr.t.test(30, d=.09792157, type="paired")This yields an observed power of 0.0813, or 8% chance of detecting a difference between the groups, given that one exists! The sample size needs to be much bigger for such a small effect. To see exactly how big, I can use the pwr package again, inputting the desired power (80% is widely considered acceptable), and letting it provide me with the sample size needed.
>pwr.t.test( d=.09792157, type="paired", power=.8)
n = 820!!! I would need 820 trials per keyboard for the test to be powerful enough to detect differences of that effect size. Well, I suppose I won't be continuing this project any time soon. I'm satisfied to know that my average WPM is 84.78 with a standard deviation of 7.77.
Saturday, December 7, 2013
Blog-nauguration, take 2
Digital Citizenship as Identity-formation
A few weeks ago, presaging (if not precipitating) my own entry into the blogosphere, I read a paper by Siles (2012) entitled "Web Technologies of the Self: The Arising of the "Blogger" Identity." This article examines the emergence of online diarists and bloggers in the late 1990s through the lens of Foucauldian "technologies of the self" by considering the role of websites as artifacts in the process of self-formation online.
According to this author, a blog is a place where
"random observations, selected links, and extended diatribes resolve into a mosaic revealing personality, a self... It is the writer's unique fusion of interests, enthusiasms, and prejudices --her personality-- that makes a weblog compelling" (Blood, 2002a)There used to be a clear distinction between bloggers and online diarists that has all but disappeared today. Originally, "weblogs" (or, after 1999, "blogs") were just curated lists of hyperlinks, often updated regularly --appended with helpful annotations, recommendations, and reviews-- and in reverse chronological order, with the newest content appearing at the top. Since their genesis, and particularly in their earlier instantiations, they appealed more to tech-savvy individuals who wanted a digital display-case for their favorite websites and geek-links, and while this is clearly a more exteriority-oriented activity than the more inward-looking act of authoring a diary, interviews by Siles (2012) revealed a common purpose. These are both places to "respond to", "comment on", or "intervene in" daily life, places for introspection, places where we can gain a new understanding of ourselves by divulging our inner world to others. Through these public, self-relevatory disclosures, we ourselves can be transformed.
Blogs, and to a lesser extent, online diaries, function as an online embodiment of hupomnemata, a material means by which to
‘‘capture the already-said, to collect what one has managed to hear or read, and for a purpose that is nothing less than the shaping of the self’’ (Foucault, 1997, p. 211).
This is my foremost motivation (1), the fons et origo, for blogging here. My hope is that, in telling some other (a generalized, inclusive "other") who I am, I'll wind up telling myself who I am, and maybe then I'll try to act as though I am who I say I am.
"Speaking aloud, as every lecturer knows, often reveals implications (and particularly problems) in one's own message that elude one when one engages in silent soliloquy" (Dennett, 1993).
Because lately, who I am is socially inert. Complaisant by nature, recently married, and voluntarily friendless, there really isn't anyone left for me to try to impress. And neither is this some new development: to find any attempts on my part to impress, or to cultivate an "impressive" persona, you'd have to look as far back as high school. And though it must have given me an edge in the mate choice department 6 years ago (my choice chose me, and it's been perfect togetherness ever since), my need-to-impress has all but atrophied from disuse. Because why bother? I'm set.
Well, it's taken some time, but I've come to realize that this attitude is no good. Like it or not
"[As human begins], our fundamental tactic of self-protection, self-control, and self-definition is not spinning webs or building dams, but telling stories, and more particularly concocting and controlling the story we tell others - and ourselves - about who we are... Our tales are spun, but for the most part we don't spin them; they spin us. Our human consciousness, and our narrative selfhood, is their product, not their source... These strings or streams of narrative issue forth as if from a single source...their effect on any audience is to encourage them to (try to) posit a unified agent whose words they are, about whom they are" (Dennett 1993, emphasis mine).
I'm going to use this blog to get to know myself better; sure, it sounds like a lot of cheese, but in time I'll be able to look at the running list of bunk I've posted and what I'll see is a glorious constellation of my own features, features that my very personhood comprises (at least, that's the hope). Going forward, in an effort to impress the collective You (and no one in particular), I am going to start taking a little more pride in my appearance. At long last I have an audience, however illusory, for which to perform.
Another way of looking at it is, that if I keep this up, I will be able to look back and see how, in each post, I have embedded fundamental aspects of my identity-at-the-time. When we write, the millions of experiences we've had since birth are brought to bear on the writing process, and so the author leaves a residue. Roswell and Pahl (2007) call this phenomenon "sedimented identities in texts." If you accept the materialist premise of no souls, no homonculi, no ghosts in the machine, etc., then eventually you must acknowledge that
"[Identities] are artifacts of the social processes that create us, and, like other such artifacts, subject to sudden shifts in status. The only "momentum" that accrues to the trajectory of a self is the stability imparted to it by the web of beliefs that constitute it, and when those beliefs lapse, it lapses, either permanently or temporarily (Dennet, 1993)
- Dennett, D. C. (1993). Consciousness Explained. Penguin Adult.
- Rowsell, J., & Pahl, K. (2007). Sedimented Identities in Texts: Instances of Practice. Reading Research Quarterly, 42(3), 388–404.
- Siles, I. (2012). Web Technologies of the Self: The Arising of the “Blogger” Identity. Journal of Computer-Mediated Communication, 17(4), 408–421. doi:10.1111/j.1083-6101.2012.01581.x
Friday, December 6, 2013
ELM-ART, an online LISP Tutor
A free web-based Intelligent Tutoring System that teaches you the basics of the LISP programming language: ELM-ART (http://art2.ph-freiburg.de/Lisp-Course)
First post: a couple links
"O Muses, O high genius, aid me now!"
-Inferno, Canto II
If you use the "highlighter" function in a .pdf reader, you might find this service helpful (sumnotes.net); with a click, it copies all of the text you've highlighted and combines it into a single file. This is certainly nontrivial, and it took me a good half-an-hour to find.
Also, if you want a quick LaTeX compiler, check this out (mathurl.com). It creates a .png based on the input and keeps your output online so you can link to it. For instance, here's a generalized form of Euler's identity:
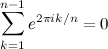
Subscribe to:
Posts (Atom)